Real-time Data Pipeline
DATA ENGINEERINGA comprehensive real-time data pipeline project focused on fraud detection using Apache Kafka for stream processing. The pipeline integrates various technologies including Docker, MongoDB, PostgreSQL, and Apache Airflow for orchestration, demonstrating a complete end-to-end data engineering solution.
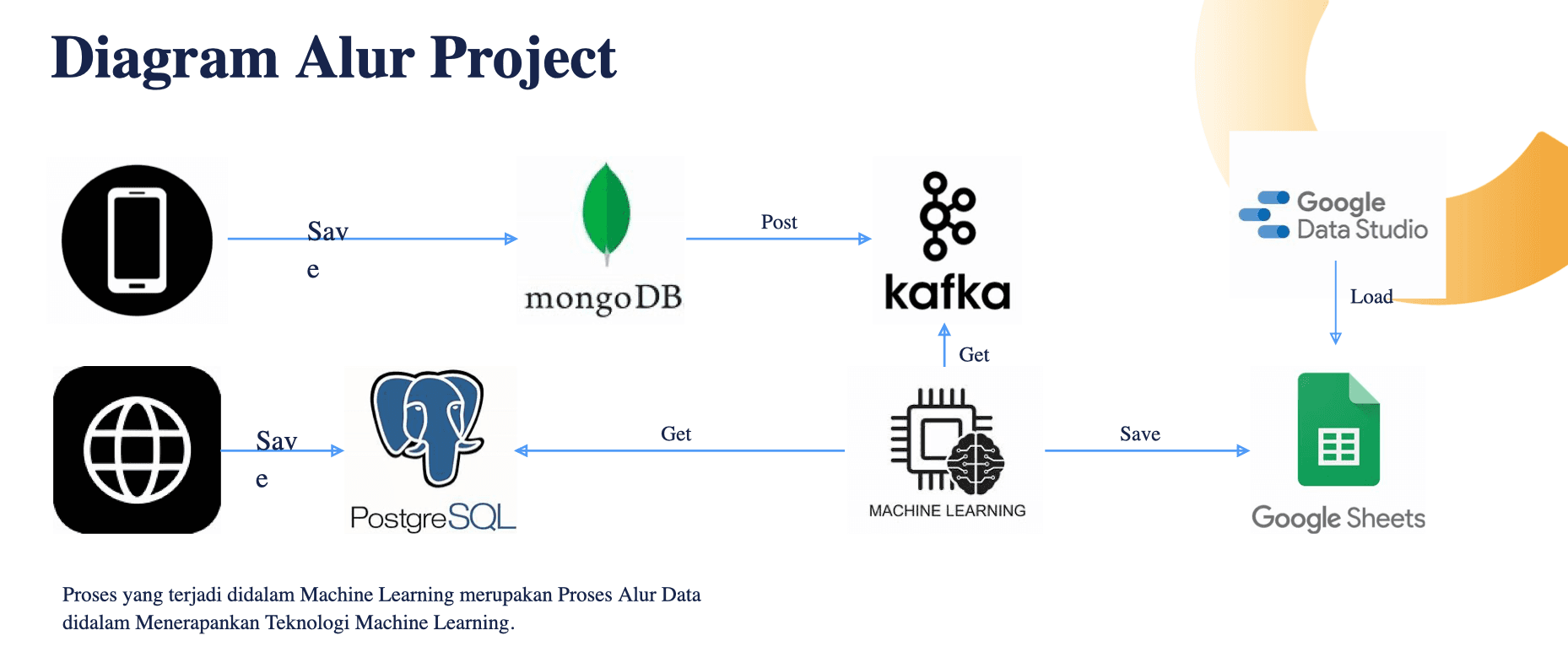
Project Highlights
- Built end-to-end real-time fraud detection pipeline
- Implemented data orchestration using Apache Airflow
- Developed stream processing with Apache Kafka
- Created visualization dashboard using Google Data Studio
Technologies Used
Project Stages
Stage 1: System Setup
Implemented system requirements including Kafka, Docker, Zookeeper, MongoDB, PostgreSQL, and Apache Airflow configuration. Created DAG python files for data orchestration.
Stage 2: Data Pipeline Development
Set up Jupyter environment for local testing, integrated FraudModel.py for transaction processing, and established data flow patterns.
Stage 3: Library Integration
Installed and configured 9 essential Python libraries in the 'DE - STREAM PROCESSING' folder, ensuring successful execution of the pipeline components.
Stage 4: Database Connection
Established PostgreSQL database connection and successfully executed data dump operations for local database population.
Stage 5: Producer Implementation
Created transaction simulation system using Kafka producer, implementing real-time data streaming to topic 'ftde01-project4'.
Stage 6: Consumer Development
Developed and optimized consumer scripts for Python 3.12.2, successfully capturing and processing streamed data.
Stage 7: Data Processing
Implemented data joining operations, converting producer data to dataframes and executing fraud predictions on the processed data.
Stage 8: Visualization
Completed the pipeline with MongoDB integration, Google Sheets export, and Google Data Studio visualization implementation.